Cómputo Científico para el Análisis de Datos
Soluciones a los ejercicios del curso
Ejercicios de Python
Tipos de datos
Listas
Ejercicio 1: Dada una lista de números, intercambia cada par de elementos adyacentes. Por ejemplo, si la lista es [1, 2, 3, 4, 5], el resultado sería [2, 1, 4, 3, 5].
Soluciones:
- Solución 1: explicación Luis
lista_1=[1,2,3,4,5,6]
par=lista_1[:-1:2]
impar=lista_1[1::2]
lista_1[:-1:2]=impar
lista_1[1::2]=par
lista_1
lista = [1, 2, 3, 4, 5]
Escribir resultado
[2,1,4,3,5]
-
Solución 2:
-
Solución Francisco Esp:
numeros = [0, 1, 2, 3, 4, 5, 6, 7, 8]
#Se cambian guardan los elementos que están en las posiciones pares o impares
pos_par = numeros[:-1:2]
pos_impar = numeros[1::2]
#Se cambian los elementos en posiciones pares por los elementos en las posiciones impares y vicesversa
numeros[:-1:2] = pos_impar
numeros[1::2] = pos_par
numeros
Resultado
[1, 0, 3, 2, 5, 4, 7, 6, 8]
Ejercicio 2: Dada una lista de letras, invierte el orden de los elementos en grupos de tres. Por ejemplo, si la lista es [‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’, ‘g’, ‘h’, ‘i’], el resultado sería [‘c’, ‘b’, ‘a’, ‘f’, ‘e’, ‘d’, ‘i’, ‘h’, ‘g’].
Soluciones:
- Solución 1(Atenea):
lista = ['a','b','c','d','e','f','g','h','i']
sublista_1,sublista_3 = lista[::3],lista[2::3]
lista[::3] = sublista_3
lista[2::3] = sublista_1
lista
- Solución Frnacisco Santiago:
```python
lista=["a","b","c","d","e","f","g","h","i"]
nueva_lista=lista[0:3][::-1] +lista[3:6][::-1]+lista[6:9][::-1]
print(nueva_lista)
```output
['c', 'b', 'a', 'f', 'e', 'd', 'i', 'h', 'g']
Diciconarios
Ejercicio 1:
1) Crea una lista que contenga los nombres de tres amigos tuyos.
2) Crea un diccionario que represente la información de un libro (título, autor, año de publicación).
3) Realiza la suma de dos números y guarda el resultado en una variable.
4) Concatena dos cadenas de caracteres y muestra el resultado.
Soluciones Francisco Santiago:
#1
amigos = [ "Andres", "Brenda", "Cecilia"]
#2
diccionario = { "título": "María", "autor": "Jorge Isaacs", "año de publicación": 1881}
#3
suma = 1+3
#4
print("cadena 1" + " cadena2")
Luis:
# 1) Crear una lista que contenga los nombres de tres amigos tuyos.
amigos = ["Mariel", "Francisco", "Karina"]
# 2) Crear un diccionario que represente la información de un libro (título, autor, año de publicación).
libro = {
"título": "La biblia de los caídos",
"autor": "Fernando Trujillo Sanz",
"año_publicación": 2010
}
# 3) Realizar la suma de dos números y guardar el resultado en una variable.
num1 = 10
num2 = 5
resultado_suma = num1 + num2
# 4) Concatenar dos cadenas de caracteres y mostrar el resultado.
cadena1 = "Hola, "
cadena2 = "¿cómo estás?"
resultado_concatenacion = cadena1 + cadena2
# Mostrar resultados
print("Ejercicio 1:")
print("Lista de amigos:", amigos)
print("\nEjercicio 2:")
print("Información del libro:", libro)
print("\nEjercicio 3:")
print("Resultado de la suma:", resultado_suma)
print("\nEjercicio 4:")
print("Resultado de la concatenación:", resultado_concatenacion)
Ejercicio 1:
Lista de amigos: ['Mariel', 'Francisco', 'Karina']
Ejercicio 2:
Información del libro: {'título': 'La biblia de los caídos', 'autor': 'Fernando Trujillo Sanz', 'año_publicación': 2010}
Ejercicio 3:
Resultado de la suma: 15
Ejercicio 4:
Resultado de la concatenación: Hola, ¿cómo estás?
Flujo de Control
##Condicionales
Ejercicio 1: Escribe un programa que verifique si un número es positivo, negativo o cero. Soluciones
Francisco Santiago:
number=0
if number > 0:
print(number, " es positivo")
elif number == 0:
print("es 0")
else:
print(number, "es negativo")
es 0
Ejercicio 2 Crea un programa que determine si un número es par o impar.
Luis:
numero = 5
if numero % 2 == 0:
print("El número es par.")
else:
print("El número es impar.")
#subir ejercicio
El número es impar.
Bucles
Ejercicio 1: Escribe un programa que muestre los números del 1 al 10 utilizando un bucle while. Soluciones
Francisco Santiago:
i=0
while i<10:
i += 1
print(i)
1
2
3
4
5
6
7
8
9
10
Ejercicio 2: ** Crea un programa que calcule la suma de los números del 1 al 100 utilizando un bucle for. **Soluciones
Luis:
suma = 0
for numero in range(1, 101):
suma += numero
print("La suma de los números del 1 al 100 es:", suma)
La suma de los números del 1 al 100 es: 5050
Interrupción
Ejercicio 1: Escribe un programa que encuentre el primer número divisible entre 7 y 5, entre 1500 y 2700.
Soluciones
Francisco Santiago:
for i in range(1500,2701):
if i%35 == 0:
print(i)
break
1505
iteración sobre secuencias
Ejercicio 1: Escribe un programa que imprima cada letra de la cadena “Python es genial”.
Soluciones
Luis:
for numero in range(1500, 2701):
if numero % 7 == 0 and numero % 5 == 0:
print(numero)
break
1505
Iteraciones sobre secuencias
Ejercicio 1 Escribe un programa que escriba las letras de la frase “Python es genial” por separado
Soluciones
Luis:
mensaje = "Python es genial"
for indice, letra in enumerate(mensaje):
print(f'Índice: {indice}, Letra: {letra}')
Índice: 0, Letra: P
Índice: 1, Letra: y
Índice: 2, Letra: t
Índice: 3, Letra: h
Índice: 4, Letra: o
Índice: 5, Letra: n
Índice: 6, Letra:
Índice: 7, Letra: e
Índice: 8, Letra: s
Índice: 9, Letra:
Índice: 10, Letra: g
Índice: 11, Letra: e
Índice: 12, Letra: n
Índice: 13, Letra: i
Índice: 14, Letra: a
Índice: 15, Letra: l
Francisco Santiago:
mensaje ="Python es genial"
caracter = enumerate(mensaje)
for i, letra in caracter:
if letra !=" ":
print(letra)
P
y
t
h
o
n
e
s
g
e
n
i
a
l
Compresiones de listas
Ejercicios
Ejercicio 1: Dada una lista de números, crea una lista que contenga los cuadrados de los números pares presentes en la lista dada.
Soluciones
Luis
numeros = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
cuadrados_numeros_pares = [x ** 2 for x in numeros if x % 2 == 0]
print(cuadrados_numeros_pares)
[4, 16, 36, 64, 100]
Francisco Santiago:
numeros=[1,2,3,4,5,6]
cuadrados_pares=[x**2 for x in numeros if x%2==0]
print(cuadrados_pares)
[4, 16, 36]
Ejercicio 2: Dada una lista de cadenas, crea una nueva lista que contenga todas las cadenas convertidas a mayúsculas. Por ejemplo, si tienes la lista siguiente:
palabras = ['hola', 'python', 'mundo', 'programación']
Lo que quieres obtener es:
['HOLA', 'PYTHON', 'MUNDO', 'PROGRAMACIÓN']
Luis:
cadenas = ['hola', 'python', 'mundo', 'programación']
cadenas_mayusculas = [cadena.upper() for cadena in cadenas]
print(cadenas_mayusculas)
['HOLA', 'PYTHON', 'MUNDO', 'PROGRAMACIÓN']
Francisco Santiago:
cadenas=["fsfgsrh", "boidntiod", "bobnrobni"]
MAYUSCULAS=[cadena.upper() for cadena in cadenas]
MAYUSCULAS
['FSFGSRH', 'BOIDNTIOD', 'BOBNROBNI']
Ejercicio 3: Dada una lista de números enteros, crea una lista que contenga solo los números primos de la lista dada, sin definir una función adicional.
Luis:
numeros_enteros = [1,2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]
numeros_primos = [numero for numero in numeros_enteros if numero > 1 and all(numero % i != 0 for i in range(2, int(numero**0.5) + 1))]
print(numeros_primos)
[2, 3, 5, 7, 11, 13]
Francisco Santiago:
primos=[x for x in numeros for i in range(x) if x!=1 and i==i ]
primos
[2, 2, 3, 3, 3, 4, 4, 4, 4, 5, 5, 5, 5, 5, 6, 6, 6, 6, 6, 6]
Numpy
Operaciones Básicas con NumPy
Ejercicio 1 Crea un array unidimensional con los números del 1 al 10 e imprímelo.
Luis
array = list(range(1, 11))
print(array)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Francisco Santiago:
array_1d = list(range(1, 11))
array_1d
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Ejercicio 2 Crea una matriz 3x3 con todos los elementos iguales a 5 e imprímela.
Luis
matriz = np.full((3, 3), 5)
print(matriz)
[[5 5 5]
[5 5 5]
[5 5 5]]
Francisco Santiago:
matriz = np.full((3, 3), 5)
print(matriz)
[[5 5 5]
[5 5 5]
[5 5 5]]
Ejercicio 3 Calcula la suma de los elementos de la siguiente matriz:
matriz = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]
Soluciones Luis
matriz = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
suma=np.sum(matriz)
print(suma)
45
Indexación y Rebanado
Ejercicio 1 Considera es siguiente array, extrae usando este tipo de indexado las letras O,M,G y W, O, Z.
np.array(list("ABCDEFGHIJKLMNOPQRSTUVWXYZ1234")).reshape(5,6)
array([['A', 'B', 'C', 'D', 'E', 'F'],
['G', 'H', 'I', 'J', 'K', 'L'],
['M', 'N', 'O', 'P', 'Q', 'R'],
['S', 'T', 'U', 'V', 'W', 'X'],
['Y', 'Z', '1', '2', '3', '4']], dtype='<U1')
** Soluciones **
Luis
array = np.array(list("ABCDEFGHIJKLMNOPQRSTUVWXYZ1234")).reshape(5,6)
letras_extraidas = array[[2, 2, 1, 3, 2, 4], [2, 0, 0, 4, 2, 1]]
print(letras_extraidas)
['O' 'M' 'G' 'W' 'O' 'Z']
Francisco Santiago:
a=np.array(list("ABCDEFGHIJKLMNOPQRSTUVWXYZ1234")).reshape(5,6)
a
a[[2,2,1],[2,0,0]]
a[[3,2,4],[4,2,1]]
array(['W', 'O', 'Z'], dtype='<U1')
Ejercicio 2 Considerea el siguiente array y extrae el array [ 5, 6, 7, 8, 9, 10, 11] usando una máscara boleana:
np.arange(12).reshape(4,3)
## array([[ 0, 1, 2],
## [ 3, 4, 5],
## [ 6, 7, 8],
## [ 9, 10, 11]])
Soluciones
Francisco Santiago:
mask = (b>5)
b[mask]
array([ 6, 7, 8, 9, 10, 11])
Ordenamiento
Ejercicio 1 Para el array a=np.ones((5,5,5)), responde lo siguiente para cada caso:
-
¿Cuál es su dimensión?
-
¿Es una vista o una copia?
Después verifica tu respuesta.
v = a[1, ::2, ::2]
v = a[2,:]
v = a[[0, 1],:]
v = a[[2,3], [2,3]]
Soluciones
import numpy as np
a = np.ones((5,5,5))
v1 = a[1, ::2, ::2]
v2 = a[2,:]
v3 = a[[0, 1],:]
v4 = a[[2,3], [2,3]]
print("Dimensiones de v1:", v1.ndim)
print("Es vista:", v1.base is a)
print("Dimensiones de v2:", v2.ndim)
print("Es vista:", v2.base is a)
print("Dimensiones de v3:", v3.ndim)
print("Es vista:", v3.base is a)
print("Dimensiones de v4:", v4.ndim)
print("Es copia:", v4.base is None)
Dimensiones de v1: 2
Es vista: True
Dimensiones de v2: 2
Es vista: True
Dimensiones de v3: 3
Es vista: False
Dimensiones de v4: 2
Es copia: True
Ejercicio 2 Ejercicio 2: Recrea los siguientes plots usando lo siguiente:
Realiza un array de solo ceros que será tu base.
Cambia los valores correspondientes a 1.
Usa plt.matshow(nombre_array) para hacer el plot.
Para importar el paquete para hacer el plot realiza lo siguiente:
%matplotlib inline
from matplotlib import pyplot as plt #libreria para hacer plots
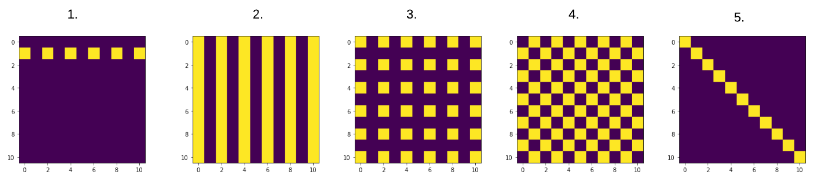
Soluciones
Luis 4
tablero = np.zeros((11, 11))
tablero[::2, ::2] = 1
tablero[1::2, 1::2] = 1
tablero_invertido = 1 - tablero
plt.matshow(tablero_invertido)
plt.show()
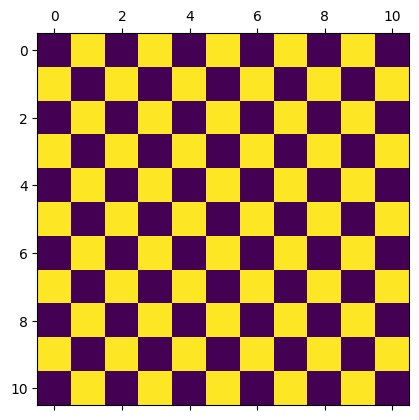
Francisco San 3
B= np.zeros(121).reshape(11,11)
B
from matplotlib import pyplot as plt
B[:,[0,2,4,6,8,10]]=1
B[[1,3,5,7,9],:]=0
plt.matshow(B)
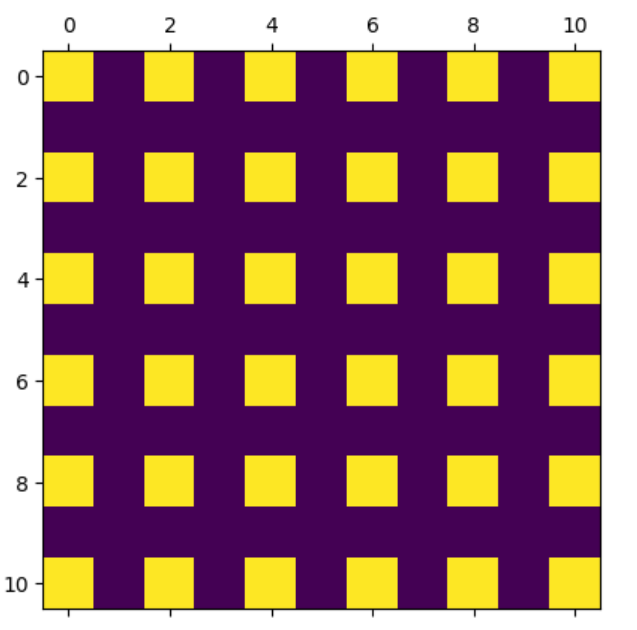
Ejercicio 3: Comienza creando un array 3x3:
ej = np.array([[6,2,3], [1,7,2], [7,6,5]])
ej
a) Ordena la última fila en forma ascenderte de manera in-place.
b) Ahora, ordena la primera y segunda columna (ascendentemente) de dos formas distintas:
-
Usando fancy-index
-
in-place, usando rebanadas o índices.
Soluciones
Luis:
ej = np.array([[6,2,3], [1,7,2], [7,6,5]])
# Ordenar la última fila en orden ascendente
ej[-1].sort()
print(ej)
import numpy as np
ej1 = np.array([[6, 2, 3], [1, 7, 2], [7, 6, 5]])
# fancy-indexing
sorted_indices_col1 = np.argsort(ej1[:, 0])
sorted_indices_col2 = np.argsort(ej1[:, 1])
ej1[:, 0] = ej1[sorted_indices_col1, 0]
ej1[:, 1] = ej1[sorted_indices_col2, 1]
# in-place
print(ej1)
ej2 = np.array([[6, 2, 3], [1, 7, 2], [7, 6, 5]])
ej2[:, 0].sort()
ej2[:, 1].sort()
print(ej2)
[[6 2 3]
[1 7 2]
[5 6 7]]
[[1 2 3]
[6 6 2]
[7 7 5]]
[[1 2 3]
[6 6 2]
[7 7 5]]
ej= np.array([[6,2,3], [1,7,2], [7,6,5]])
ej
ej[-1] = np.sort(ej[-1])
print(ej[-1])
#inciso b
#con fancy index
print(ej[0][[1,2,0]])
print(ej[1][[0,2,1]])
#con in-place
sorted_cols = np.sort(ej, axis=0)
array([5, 6, 7])
[2 3 6]
4.8 Visualización de datos
4.8.2.2 Scatter plot o gráfico de dispersión
Ejercicio 1: Usando seaborn, carga la base de datos iris y crea un gráfico de dispersión con matplotlib (sin dividir por color la especie) de la longitud del sepalo vs la anchura del sepalo.
import seaborn as sns
# Cargar el conjunto de datos de iris
iris = sns.load_dataset('iris')
Soluciones:
Luis:
plt.figure(figsize=(8, 6))
plt.scatter(iris['sepal_length'], iris['sepal_width'])
plt.xlabel('Longitud del Sépalo (cm)')
plt.ylabel('Anchura del Sépalo (cm)')
plt.title('Longitud del Sépalo vs Anchura del Sépalo')
plt.show()

Francisco
# Definimos los datos
x = iris["sepal_length"]
y = iris["sepal_width"]
#colores
species_colors = {'setosa': 'blue', 'versicolor': 'green', 'virginica': 'red'}
sizes = 100 # Tamaño de los marcadores
plt.figure(figsize=(8,6))
plt.scatter(x, y, s=sizes, alpha=0.3, cmap="hsv")
METELE IMAGEN
Ejercicio 2: Usando la base de datos penguins de seaborn crea el siguiente gráfico de dispersión.

Soluciones:
import seaborn as sns
import matplotlib.pyplot as plt
penguins = sns.load_dataset("penguins")
plt.figure(figsize=(8, 6))
plot = sns.scatterplot(x="bill_length_mm", y="bill_depth_mm", hue="species", palette="viridis", data=penguins)
plt.xlabel("Longitud del pico (mm)")
plt.ylabel("Profundidad del pico (mm)")
plt.title("Relación entre Longitud y Profundidad del Pico")
plt.grid(True)
plt.legend(loc = 'lower left')
plt.show()

4.8.2.3 Gráfico de barras
Ejercicio: Usando la base de datos penguins de seaborn, crea un gráfico de barras que muestre la cantidad promedio de pingüinos de cada especie en la base de datos.

Soluciones:
import seaborn as sns
import matplotlib.pyplot as plt
data = sns.load_dataset("penguins")
plt.figure(figsize=(8, 6))
sns.barplot(x="species", y="bill_length_mm", data=data, hue="species", palette="viridis")
plt.xlabel("Especie")
plt.ylabel("Longitud de pico (mm)")
plt.title("Promedio de longitud del pico por especie")
plt.show()

4.8.2.4 Gráfico de pastel
Ejercicio: Usando la base de datos penguins de seaborn, crea un gráfico de pastel que muestre la proporción de cada especie de pingüino en la base de datos.

**Soluciones: ** Luis:
import seaborn as sns
import matplotlib.pyplot as plt
penguins = sns.load_dataset("penguins")
species_counts = penguins['species'].value_counts()
plt.figure(figsize=(8, 6))
plt.pie(species_counts, labels=species_counts.index, autopct='%1.1f%%', startangle=140)
plt.title('Proporción de especies de pingüinos')
plt.axis('equal')
plt.show()

4.8.2.5 Boxplot
Ejercicio: Usando la base de datos penguins de seaborn, crea un boxplot que compare las longitudes del pico para cada especie de pingüino en la base de datos.

Soluciones: Luis:
import seaborn as sns
import matplotlib.pyplot as plt
penguins = sns.load_dataset('penguins')
plt.figure(figsize=(10, 6))
sns.boxplot(x='species', y='bill_length_mm', data=penguins, hue="species")
plt.title('Comparación de longitudes del pico por especie de pingüino')
plt.xlabel('Especie')
plt.ylabel('Longitud del pico (mm)')
plt.show()

4.8.2.6 Histograma
Ejercicio: Usando la base de datos penguins de seaborn, crea un histograma que muestre la distribución de las longitudes del pico para todas las especies de pingüinos.

**Soluciones: **
penguins = sns.load_dataset('penguins')
plt.figure(figsize=(8, 6))
sns.histplot(data=penguins, x='bill_length_mm', bins=20, kde=True,hue="species")
plt.title('Distribución de Longitudes del Pico')
plt.xlabel('Longitud del Pico (mm)')
plt.ylabel('Frecuencia')
plt.show()

4.8.2.8 Imshow
Ejercicio: Supongamos que tenemos la siguiente función:
[ f(x, y) = \sin(x) \cdot \cos(y) ]
-
Generar una cuadrícula de valores para ( x ) y ( y ) en el rango de ([-2\pi, 2\pi]).
-
Calcular los valores de la función ( f(x, y) ) para cada par de puntos ( (x, y) ).
-
Visualizar la función utilizando
imshowpara mostrar la función como una imagen ycontourpara mostrar las curvas de nivel. -
Tu resultado debe ser similar al siguiente:

Soluciones:
import numpy as np
import matplotlib.pyplot as plt
num_points = 100
x_valores = np.linspace(-2 * np.pi, 2 * np.pi, num_points)
y_valores = np.linspace(-2 * np.pi, 2 * np.pi, num_points)
x_grid, y_grid = np.meshgrid(x_valores, y_valores)
z_valores = np.sin(x_grid) * np.cos(y_grid)
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(z_valores, extent=[-2*np.pi, 2*np.pi, -2*np.pi, 2*np.pi], cmap='viridis')
plt.colorbar()
plt.title('Imagen de f')
plt.subplot(1, 2, 2)
plt.contour(x_grid, y_grid, z_valores, cmap='viridis')
plt.colorbar()
plt.title('Curvas de Nivel')
plt.tight_layout()
plt.show()

4.9 Data frames con pandas
Ejercicios:
- Crea un DataFrame con información sobre empleados, incluyendo Nombre, Edad y Salario. Muestra las primeras 5 filas.
- Añade una nueva columna llamada ‘Departamento’ al DataFrame de empleados.
- Encuentra el empleado más joven en el DataFrame.
- Filtra los empleados que tienen un salario mayor a $50000.
- Ordena los empleados por salario en orden descendente.
Soluciones:
Luis
import pandas as pd
# 1
datos_empleados = {
'Nombre': ['Luis', 'María', 'Francisco', 'Raul', 'Karina'],
'Edad': [30, 25, 35, 28, 40],
'Salario': [60000, 55000, 70000, 48000, 80000]
}
df_empleados = pd.DataFrame(datos_empleados)
print("Primeras 5 filas del DataFrame de empleados:")
print(df_empleados.head())
# 2
departamentos = ['Ventas', 'Marketing', 'TI', 'Recursos Humanos', 'Ventas']
df_empleados['Departamento'] = departamentos
# 3
empleado_mas_joven = df_empleados[df_empleados['Edad'] == df_empleados['Edad'].min()]
print("\nEmpleado más joven:")
print(empleado_mas_joven)
# 4
empleados_altos_salarios = df_empleados[df_empleados['Salario'] > 50000]
print("\nEmpleados con salario mayor a $50000:")
print(empleados_altos_salarios)
# 5
df_empleados_ordenados = df_empleados.sort_values(by='Salario', ascending=False)
print("\nEmpleados ordenados por salario en orden descendente:")
print(df_empleados_ordenados)
Primeras 5 filas del DataFrame de empleados:
Nombre Edad Salario
0 Luis 30 60000
1 María 25 55000
2 Francisco 35 70000
3 Raul 28 48000
4 Karina 40 80000
Empleado más joven:
Nombre Edad Salario Departamento
1 María 25 55000 Marketing
Empleados con salario mayor a $50000:
Nombre Edad Salario Departamento
0 Luis 30 60000 Ventas
1 María 25 55000 Marketing
2 Francisco 35 70000 TI
4 Karina 40 80000 Ventas
Empleados ordenados por salario en orden descendente:
Nombre Edad Salario Departamento
4 Karina 40 80000 Ventas
2 Francisco 35 70000 TI
0 Luis 30 60000 Ventas
1 María 25 55000 Marketing
3 Raul 28 48000 Recursos Humanos
4.9.2 pivot y pivot_table
Ejercicio 1:
Carga el conjunto de datos ‘titanic’ de Seaborn y utiliza pivot para reorganizar los datos de manera que las filas representen la clase de pasajeros y las columnas representen el sexo de los pasajeros, con los valores siendo la tarifa media pagada por cada grupo.
Soluciones:
Luis
pivot_tabla_resultados = titanic_datos.pivot_table(index='pclass', columns='sex', values='fare', aggfunc='mean')
pivot_tabla_resultados
sex female male
pclass
1 106.125798 67.226127
2 21.970121 19.741782
3 16.118810 12.661633
Ejercicio 2:
Utiliza pivot_table para calcular la cantidad total de sobrevivientes agrupados por clase y género en el conjunto de datos ‘titanic’.
Luis
pivot_table_result = titanic_data.pivot_table(index='class', columns='sex', values='survived', aggfunc='sum', margins=True)
pivot_table_result
sex female male All
class
First 91 45 136
Second 70 17 87
Third 72 47 119
All 233 109 342
4.11 Funciones y scripts
4.11.3 Test
Ejercicio 1: Crea un test que verifique dos funciones, una de aritmética básica (igualdad entre dos números y multiplicación entre dos números) y la otra función la longitud de elementos de una lista. Realiza el test de ambas funciones con pytest.
Soluciones: Luis
def aritmetica_basica_igual(num1, num2):
return num1 == num2
def aritmetica_basica_multiplicar(num1, num2):
return num1 * num2
def longitud_lista(lista):
return len(lista)
def test_aritmetica_basica_igual():
assert aritmetica_basica_igual(3, 3) == True
assert aritmetica_basica_igual(5, 7) == False
def test_aritmetica_basica_multiplicar():
assert aritmetica_basica_multiplicar(2, 3) == 6
assert aritmetica_basica_multiplicar(4, 0) == 0
def test_longitud_lista():
assert longitud_lista([1, 2, 3, 4]) == 4
assert longitud_lista([]) == 0
test_aritmetica_basica_igual()
Ejercicio 2: Crea un archivo nuevo para hacer test llamado test_prueba. Realiza una función prueba que verifique que 1+2 es 3. Realiza el test. Ahora prueba con 1.1+2.2 es 3.3, usa pytest.
Soluciones:
def suma(a,b):
return a+b
def test_sumar_positivos():
#veririficar suma de positivos
resultado= suma(1,2)
assert resultado== 3, f"la suma deberia ser 3 pero paila {resultado}"
4.14 Programación en paralelo
Ejercicio: Crea una función para calcular el cuadrado de una lista de números. Ejecutala con %%time para comparar tiempo de ejecución y recursos de las dos maneras, usando paralelización y sin esto.
Soluciones: Luis
import time
def cuadrado(x):
return x ** 2
# Creamos una lista de números
numeros = [1, 2, 3, 4, 5]
#numeros = np.arange(1, 1001)
inicio_map = time.time()
resultados_map = map(cuadrado, numeros)
print("Resultados con map:", list(resultados_map))
fin_map = time.time()
tiempo_map = fin_map - inicio_map
print("Tiempo con map:", tiempo_map, "segundos")
Resultados con map: [1, 4, 9, 16, 25]
Tiempo con map: 0.0007224082946777344 segundos
Luis 5740c6c94817a09c5054098b2b482db2dad060e3